浅谈文轩网双十一背后的技术支撑
背景
2015年双十一,文轩网单日销售码洋破亿,这对于五年前整年销售才千万级的公司来讲的确是个很大的进步。
从天猫统计的数据来看,双11当天图书的销售额在2.6亿左右,其中新华文轩天猫店排行第一,占去了接近一半的销售额,身后还有当当、博库等众多业界的强手,文轩网虽然坐落在天府成都,作为一家线上图书销售企业发展到今天,线下在全国有三大物流仓储,线上具备了互联网多渠道多平台的销售实力,其实你在互联网上 进行图书购买,小到一家淘宝集市的店铺,大到京东、当当、亚马逊,远到西欧,你的图书都有可能是来源于文轩网,因为B2B/B2C都在我们的业务中占比很 大,除了我们的自营网络平台、我们还有各大电商平台的直营店铺、我们还为各大电商平台批量供应优质图书甚至为很多中小卖家提供资源和技术支持,是不是和种 花家一样很腹黑..
要从市场份额中占有一席之地,除了业绩部门的不断奋战,还有站在背后的技术力量,在双十一业务过亿的时刻,文轩网的系统产生了近百万的订单、近千万次的商品更新、超过三千万的外部消息以及过亿的内部系统及服务调用。
发展
在公司业务特点下,技术部门的主要挑战便是去满足多条业务线的不断变化和发展,简言之就是业务要的功能没有然而现在的功能又满足不了,那面对这些的业务和挑战,文轩网的系统是个什么样的状况?
先从一年前的系统数据流转的角度来看一下相关的系统结构:

上图是一张2014年的数据流转图,主要针对图书相关的数据流转先做个介绍,例如商品信息、库存、交易订单.
从图上可以看出来,其实针对多业务线的情况,我们将系统也根据业务线进行了一些划分,比如直销系统负责处理自营平台的业务、综合渠道负责处理对接外部电商店铺的业务功能、还有供货渠道和组织销售分别去对应外部企业和中小卖家,各种差异化的业务特性会通过这些子系统去做转换和处理,例如将核心的商品信息转换成不同渠道的商品标准、收集不同渠道的订单信息转换成核心的订单标准。
不管是正向、逆向的数据,会通过调度、消息的方式来实现实现不同的业务的数据流转,例如商品同步、库存更新、价格更新、订单传输等等,在这个过程中,业务数据可以通过数据库、消息服务器、缓存服务器、文件等多种形式进行交互,多样性保证了数据的时效和格式都能够适配目标系统又做到不相互影响,但也给基础设施的维护和扩展上带来了诸多不便。
整体的系统结构归纳起来是这样的:
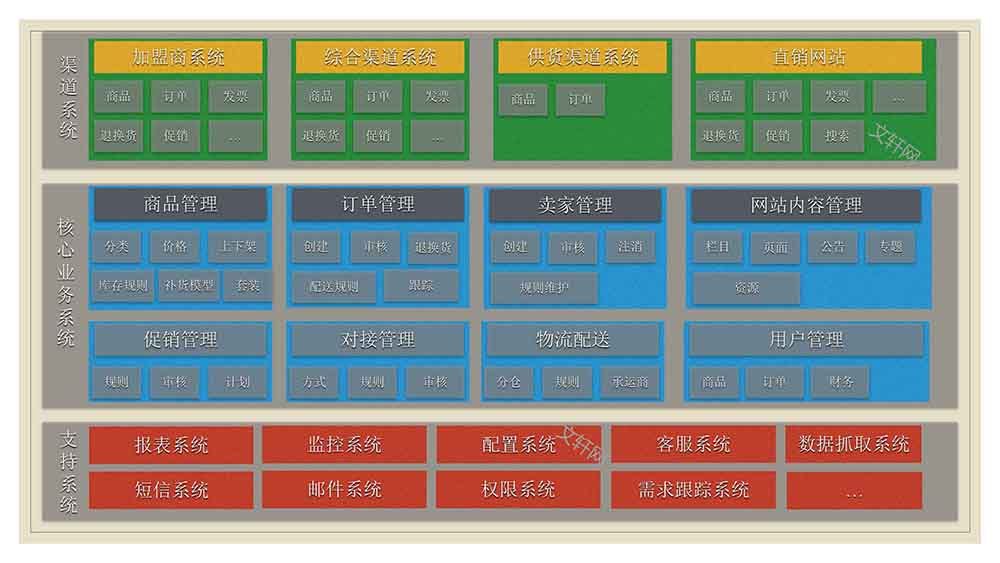
整体来看还是比较清晰,三层系统:渠道系统、核心业务系统、基础支撑系统。
自研发的系统基本是基于Java生态的B/S系统,采用了简单的MVC结构,2011年开始MVC使用SpringMVC、Spring、Hibernate来作为基础架构.对于公用的组件和业务逻辑,使用传统的包依赖方式,基础设施包括Memcache、Redis、ActiveMQ等中间件。
在这套架构下,再加上研发相关的一些规范和流程,在当时也还是很好的满足了文轩网各业务线的功能支撑和性能要求,结构简单、 方便开发、测试,业务响应快。但随着业务发展,也有很多问题暴露了出来,例如业务线之间耦合太过紧密,特别是针对基础业务,通过包依赖导致单条业务线的调整,需要评估的影响范围过大。
例如综合渠道的某个商品规则调整,需要评估综合渠道内各子渠道的影响,比如天猫、京东等.如果涉及到核心的商品标准做调整,还要将评估范围扩大到直销渠道、供货渠道等。
这也只是开发层面的痛点之一,在运维、部署上带来的成本花销也较大,例如权限、日志、依赖版本更新等。
演进
在2015年开始,为了解决原有系统结构上的不足,结合互联网行业的一些成熟方案,技术部门决定引入SOA,对已有的业务系统进行逐步改造和更新,主要解决业务耦合、系统耦合、系统瓶颈带来的系统挑战。通过近几年的系统建设经验和对业务的重新梳理,对现有系统功能进行了服务划分:
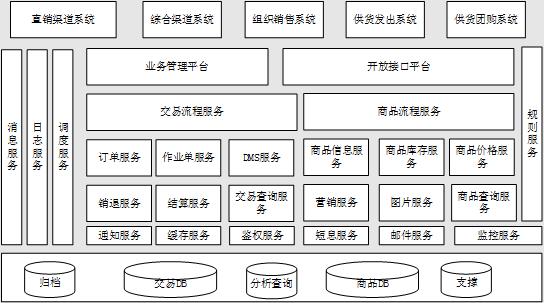
对现有业务系统根据业务进行垂直拆分,形成以交易流程服务和商品流程服务为中心的交易基础服务组和商品基础服务组,
公用组件和基础组件下沉到基础设施服务中去,例如日志、消息和通知等应用。
数据层对原有的数据也进行垂直拆分,形成了商品数据库、交易数据库用来完成多渠道的数据管理,增加了分析库和支撑库,用来做跨库的查询或者ETL离线分析。
服务层的管理我们选择行业中比较通用的Dubbo,其具备的服务发现、负载均衡、服务监控等特性这里不再细说,结合Spring-Boot的开箱即用来搭建基础服务,把更多的精力投入到业务研发,这里会引入一个问题,是基础服务,而不是微服务,后者要求的拆分粒度会更细,但在业务改造过程我们觉得并不适合这种方式,步子太大会磕到。
在中间件方面除了上面提到的memcache/redis/activemq等,还引入了storm来处理实时数据,例如监控数据、日志数据,双十一的实时业务监控地图、战报图等就是它的应用场景之一。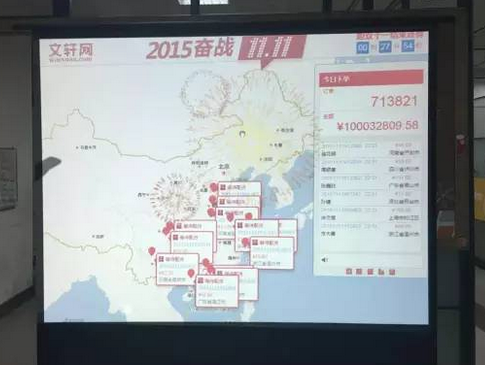
服务化后,运维部署也需要进行相应的跟进,目前实现了服务多节点、Storm拓扑等在jenkins的平滑发布,同时引入Docker对部分应用进行容器化部署和管理。
在解耦、拆分的过程中,我们也发现越来越多的服务会让之后的治理变得颇为复杂,这里提了几点规范:
- 流程服务之间可以相互依赖,基础服务间不允许依赖.
- 针对业务形成标准模型,各服务通用一致的基础模型进行数据封装和组合.
- 针对原有业务无法服务化,结合原有功能搭建过渡服务来解决耦合的问题。
然后演进过程中服务依赖的一个快照是这样的:
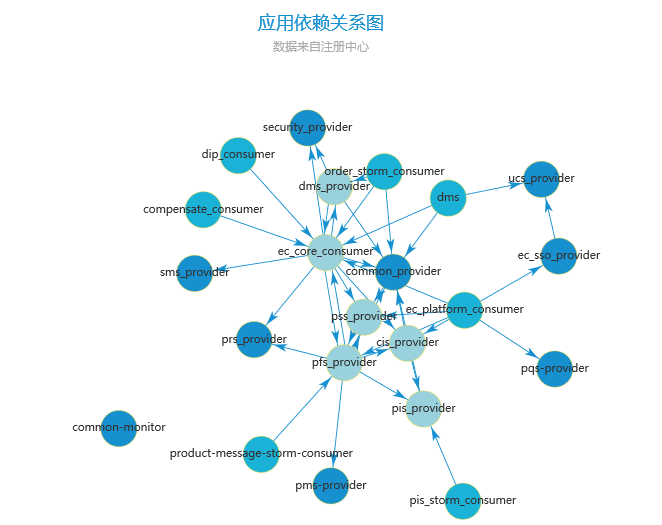
看图还是有些混乱,其中ec-core-consumer就是遗留系统的一个依赖包,一些强制的功能依赖通过common-provider这个临时服务来处理,其他服务调用common-provider的接口则可完成处理,而不需要依赖原来的具体逻辑。
目前的文轩网演进就是在这种方式下去一步步实现服务化、业务解耦、数据拆分,在双十一节前,已经完成了对商品相关的应用改造工作,完成图中商品相关的服务建设,并对原有系统的商品功能和逻辑平滑的迁移到商品服务组,对于涉及用户界面的功能,我们也开发了新的管理平台来应对,即上图中的业务管理平台。
管理平台本身不会包含业务逻辑也不依赖底层数据库,所有逻辑都通过后端的流程服务或者基础服务来实现,主要实现用户交互、数据收集、数据管理的作用,涉及的技术主要还是Spring-MVC、AngularJS,选择AngularJS由于它前端MVC思想比较贴近Java的开发生态,学习曲线低,分层的思想更加方便隔离视图和逻辑。
小结
文轩网的技术体系到这里基本上介绍完了,场景并未深入进去,细节放到之后的博文里去写吧,例如库存服务、基础服务的ORM选型、前端的体系等,还有一些遗留的工作没来得及去做,比如日志的规范、日志的收集、监控预警等。
通过服务化的一些改造,的确让系统的维护、扩展性上带来提升,但同时也带来更多的开发、测试工作量,对团队的配合和面向接口编程的能力也提出了更高的要求。