Storm学习笔记二
前面了解了Storm的一些基本概念,这篇笔记来搭建一个日志收集系统,Storm在系统中充当一个管道和过滤器,实现从Redis上读取数据,并进行数据索引。
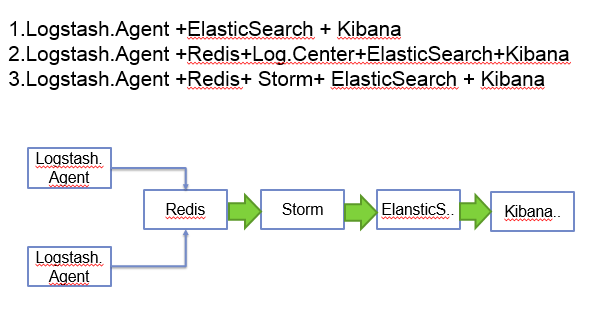
这是架构的一个演变,通过第一种方式,就能实现最基本的日志收集和展示,这里加入redis和storm,提高系统的性能和扩展性。
依赖环境:
- JDK1.6.X
- Logstash-1.4.2
- ElasticSearch 0.9
- Kibana-3.1.2
- Redis
- Storm
- ZeroMQ
- Jzmq
- Zookeeper
需要自己实现的处理逻辑类:
LogSpout : 从Redis持续的读入日志信息,并封装输出给Stream
public class LogSpout extends BaseRichSpout{
private static Logger LOG = Logger.getLogger(LogSpout.class);
private Jedis jedis;
private SpoutOutputCollector collector;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
jedis = new Jedis(Conf.DEFAULT_JEDIS_HOST,Integer.parseInt(Conf.DEFAULT_JEDIS_PORT),2000);
this.collector = collector;
}
@Override
public void nextTuple() {
String content = jedis.rpop("logstash.test");
if(StringUtils.isEmpty(content)) {
Utils.sleep(1000);
}else {
JSONObject jsonObject = (JSONObject) JSONValue.parse(content);
LogEntry entry = new LogEntry(jsonObject);
collector.emit(new Values(entry));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields(LogEntry.LOG_ENTRY));
}
LogRulesBolt:接收Stream中LogSpout的输出信息,并利用规则对内容调整过滤
public class LogRulesBolt extends BaseRichBolt {
private static final long serialVersionUID = 1L;
public static Logger LOG = Logger.getLogger(LogRulesBolt.class);
private StatelessKnowledgeSession ksession;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder();
kbuilder.add( ResourceFactory.newClassPathResource("/Syslog.drl",getClass()), ResourceType.DRL );
if (kbuilder.hasErrors() ) {
LOG.error(kbuilder.getErrors().toString() );
}
KnowledgeBase kbase = KnowledgeBaseFactory.newKnowledgeBase();
kbase.addKnowledgePackages( kbuilder.getKnowledgePackages() );
ksession = kbase.newStatelessKnowledgeSession();
}
@Override
public void execute(Tuple input) {
LogEntry entry = (LogEntry)input.getValueByField(LogEntry.LOG_ENTRY);
if(entry == null){
LOG.info( "Received null or incorrect value from tuple" );
return;
}
ksession.execute(entry);
System.out.println(entry.isFilter());
if(!entry.isFilter()){
LOG.debug("Emitting from Rules Bolt");
collector.emit(new Values(entry));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields(LogEntry.LOG_ENTRY));
}
}
IndexerBolt: 接收Stream中LogRulesBolt输出的信息,并调用远程ElansticSearch进行索引
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
Settings settings = ImmutableSettings.settingsBuilder().put("client.transport.sniff", true)
.put("cluster_name", "elasticsearch").build();
client = new TransportClient(settings).addTransportAddress(new InetSocketTransportAddress("10.100.15.177", 9300));
this.collector = collector;
}
@Override
public void execute(Tuple input) {
LogEntry entry = (LogEntry) input.getValueByField(LogEntry.LOG_ENTRY);
if(entry == null){
LOG.fatal("Received null");
return;
}
String toBeIndexed = entry.toJson().toJSONString();
if(!StringUtils.isEmpty(toBeIndexed)) {
LOG.info(toBeIndexed);
IndexResponse response = client.prepareIndex(INDEX_NAME, INDEX_TYPE).setSource(toBeIndexed)
.execute().actionGet();
if(response == null) {
LOG.error(String.format("Filed to index Tuple: %s", input.toString()));
}else {
if(response.getId() == null) {
LOG.error(String.format("Filed to index Tuple: %s", input.toString()));
}else {
collector.emit(new Values(entry,response.getId()));
}
}
}
}
LogTopology: 封装执行步骤
private TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("logSpout", new LogSpout(),1);
builder.setBolt("logRules", new LogRulesBolt(), 1).shuffleGrouping("logSpout");
builder.setBolt("indexer", new IndexerBolt(), 1).shuffleGrouping("logRules");
StormSubmitter.submitTopology(name, conf, builder.createTopology());
注意事项:
- 代码编译的JDK版本需要和Storm部署环境一致
- 需要将应用依赖打包提交
- 和Storm重复的Jar依赖需要通过scope=provided的方式隔离
- 和Storm依赖版本冲突的jar,以Storm的为准
提交命令:
./storm jar ../wx/hh.storm.jar com.winxuan.storm.log.LogTopology logStorm
提交后,Storm会一直执行LogSpout的nextTuple方法,从redis中获取指定key的日志信息,如果没有读取到则休眠1s,
读取到的日志被封装成自定义的日志对象,并提交给storm集群的stream,后续的rulesbolt和indexbolt分别从stream中拿到属于自己的tuple进行数据过滤以及数据索引。
正常执行的数据会被成功的索引到ElasticSearch,通过Kibana的API图形化界面,自定义一个面板,我们就能看到通过agent收集过来的日志信息,并能进行相应的图表展示和检索。

—